From time to time one might stumble upon a neat music playlist, evidently picked with love, patience and surgical precision, sadly encapsulated in an image
e.g:
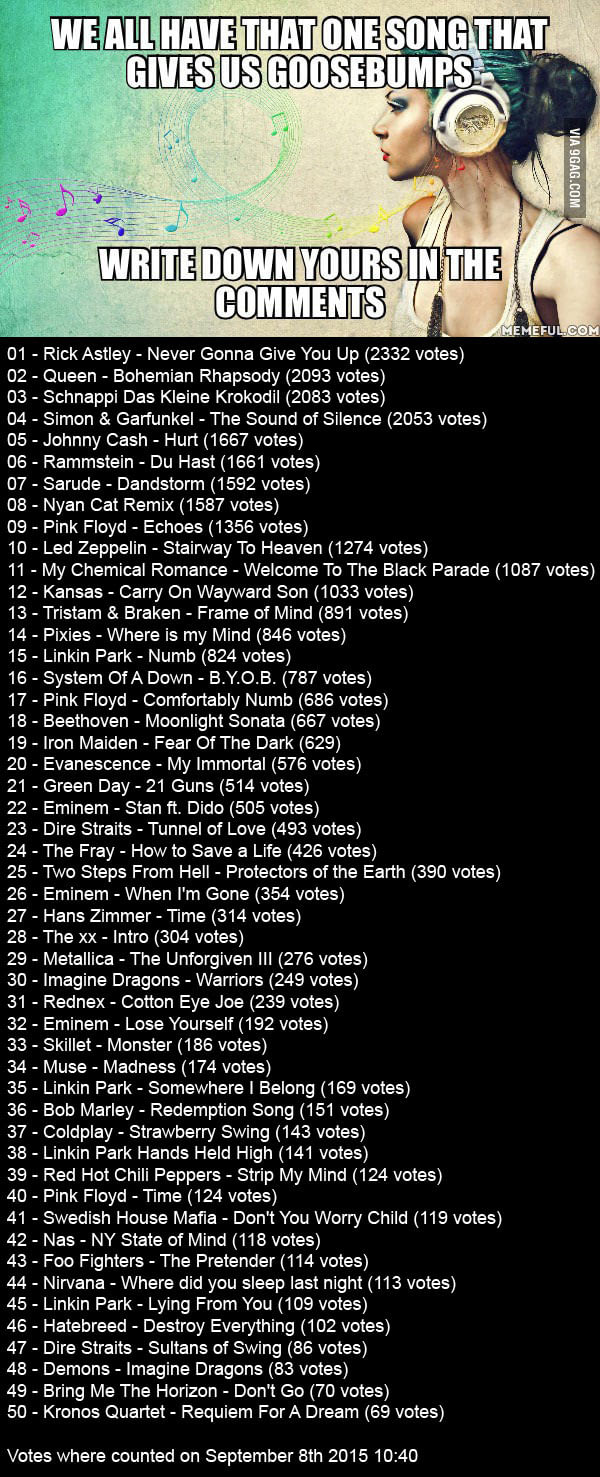
src: 9GAG
Someone wanted to share a perfect mix with the world, created appropriate graphics to go alongside songs, published it and felt majestically artistic
The only downside of this approach is that, obviously, you can’t select songs and copy / paste them in YouTube… at least not without a few lines of code
After 9 commits
So what do we need?
- A way to interpret relevant text from image playlists
- A website that can provide audio, based on retrieved matches
Initial POC incorporated a free online Optical character recognition solution (OCR.SPACE) and used sequential processing on identified songs. From there, text detection was directed offline with powerful Tesseract, while Goroutines satisfied thirst for the speed
For actual song fetch, local youtube-dl was used, app that requires YT video ID (part after youtube.com/watch?v=), while Google’s YouTube Data API v3 was employed for obtaining that piece of the puzzle
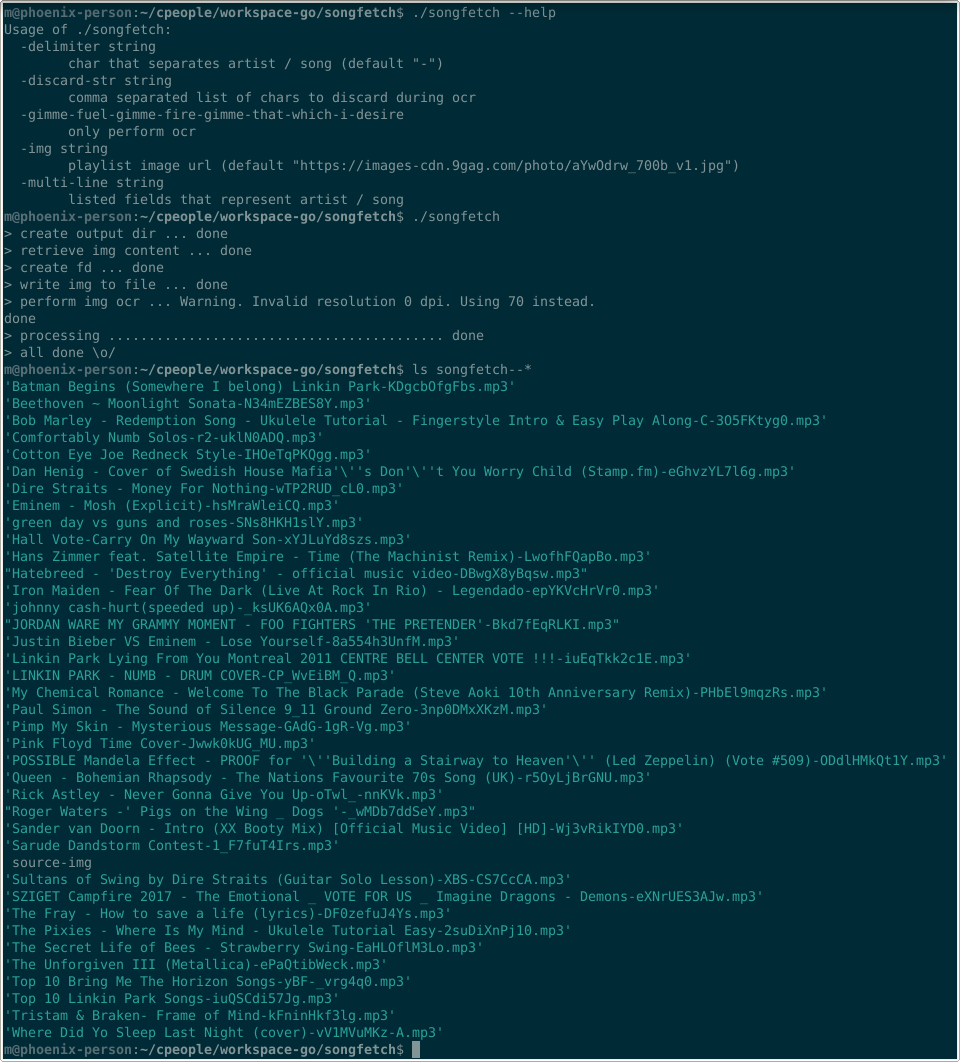
All patched up – with quite simple usage and logical parameters:
m@phoenix-person:~$ ./songfetch --help
Usage of ./songfetch:
-delimiter string
char that separates artist / song (default "-")
-discard-str string
comma separated list of chars to discard during ocr
-gimme-fuel-gimme-fire-gimme-that-which-i-desire
only perform ocr
-img string
playlist image url (default "https://images-cdn.9gag.com/photo/aYwOdrw_700b_v1.jpg")
-multi-line string
listed fields that represent artist / song“Experimental” multi-line support was initially creating a slice of (artist,
song) structs, expecting them in the order provided on the start, e.g:
--multiLine 'Band:,Song:', with string portrayal of mappings and their
positioning (which one comes first)
Problem with this approach is that Tesseract doesn’t always identify text entirely, which can lead to inaccurate mappings (e.g. 13 scanned artists and 11 recognized songs)
Solution? Simply gather all readable songs and artists and search for all possible combinations:
Within Temptation - lateralus
Within Temptation - Hush
Within Temptation - Ice Queen
TOOL - lateralus
TOOL - Hush
TOOL - Ice Queen
Deep Purple - lateralus
Deep Purple - Hush
Deep Purple - Ice QueenHere only 4 are valid, since Deep Purple and Tool actually do share a song title (Hush), while the remaining 6 should return no results
Search over such list, besides correctly matched, returns similar songs (as in different tracks from the same artist), but also potential manure, since YouTube API insists on giving something back, no matter how irrelevant
i.e.
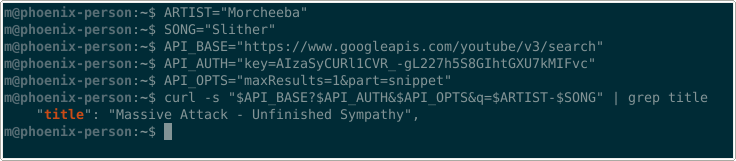
This song is the hero we deserve, but not the one we need right now
Pics or It Didn’t Happen
Processing playlists ranges from surprisingly good to absolute

src: Wikipedia
The Ugly
For (sadly) less popular content (try metal playlists), Google’s API is the bottleneck. Songfetch will happily retrieve tracks with any video ID, but these might be off-target if something that sounds similar is more popular, based on YT Data
So, if everything fails, there is the obligatory OCR-only flag
(--gimme-fuel-gimme-fire-gimme-that-which-i-desire) that can be
passed to songfetch to solely display recognized lines
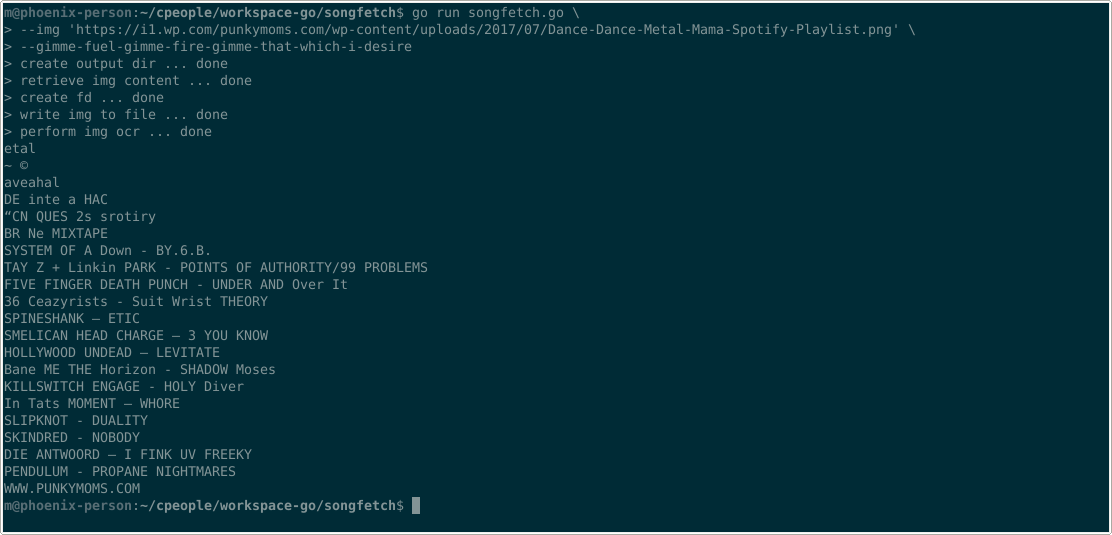
The Bad
As mentioned, YouTube dAPI-3 derives quality results most of the time, but force-feeds responses in nearly all cases, even if query was nonsense
Further more, OCR adds it’s own layer of variability to the equation
In more “picture heavy” playlists, Tesseract frequently neglects some lines and misinterprets others, often resulting in random clips being transcoded to mp3
The Good
It works most of the time™
Majority of tested images yielded good results
Even the songs from handwritten playlists can be partially claimed:

src: 8tracks.com
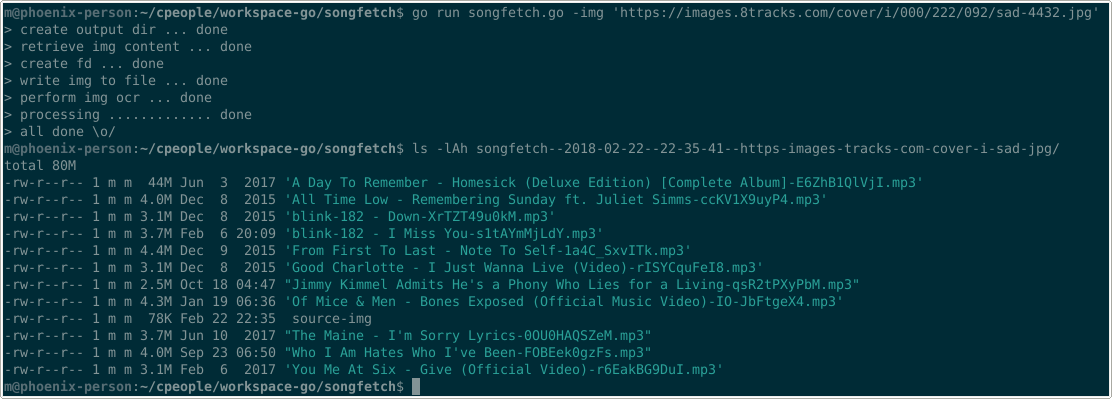
6 perfect hits, 4 partial (alternate song / artist), 4 !recognized, 1 jolly miss (‘Hear You Me - Jimmy Eat World’ != ‘Jimmy Kimmel Admits He’s a Phony Who Lies for a Living’)
TL;DR
If playlists are stored as images – use songfetch, otherwise – thank Bill
