There are plenty of resources on Machine Learning and Neural networks, and many interactive playgrounds where you can learn and test out ML concepts. If you still need references before going further – check out the basics
Recurrent neural networks (RNNs), present a artificial NN type in which units go through a directed cycle, allowing dynamic change of arbitrary sequences with it’s internal memory
Traditional (feed-forward) neural networks treat all inputs and outputs as independent pieces, which, most of the time, is not the case. Imagine predicting next character in a word without knowing the preceding one
That’s where RNNs come in place, with output of subsequent task directly dependent on the previous

This IO coupling allows RNNs to thrive in handwriting and speech recognition, in addition to being able to easily train character-level language models
The last part, in layman’s terms – if we feed RNN with bunch of text, it’ll model probability distribution of each character in a sequence, allowing us to create new text snippets, char by char
Karpathy RNN
When you mix Torch framework and Lua code, good things happen
Mr Andrej Karpathy nicely documented everything in his blog, shared code behind it and provided detailed guide on how to prepare and work with his RNN implementation
Karpathy’s blog post covers awesome examples of the effectiveness of his neural network, accompanied by general guidelines on backpropagation, operating on sequences of vectors, as well as speeding things up with CUDA on nVIDIA GPUs
Bootstrapping whole enchilada, however, is a bit time consuming and ain’t promptless, so let’s automate things a bit
The bootstrap
setup-rnn.sh to the rescue – installing required system packages, fetching everything Torch related, removing user inquiry from install, retrieving Lua modules and finally cloning Karpathy’s char-rnn repo
Script is designed with 4 initial distros provided by Amazon EC2 in mind:
- Amazon Linux
- SUSE Linux Enterprise Server
- Red Hat Enterprise Linux
- Ubuntu Server
Linux versions and AMIs on which bootstrap was tested, respectably:
- 2017.09.1 (32cf7b4a)
- 12 SP3 (6bc56f13)
- 7.4 (223f945a)
- 16.04 LTS (1ee65166)
On any of these flavors, bootstrap is an oneliner that grabs code from GH and orchestrates everything needed for char-rnn:
curl https://raw.githubusercontent.com/ushtipak/rnn-bootstrap/master/setup-rnn.sh | sudo bashOther distros, ones not using apt, yum or zypper, can still use boostrap
script by simply adding a flag ./setup-rnn.sh --ommit-dependency-installation
and the list of system packages required will be displayed on start of it’s run
In any case, after 40-ish lines bash script completes it’s run, Torch framework
is installed in /opt/torch/, while the repo ends up in /opt/rnn-karpathy
Digits
In order to be consistent and have credible numbers, bootstrap was performed three times on each of the four default EC2 Linux flavors
upper left to lower right: Amazon, SUSE, RHEL, Ubuntu
Two things are interesting here – time to prepare everything and time to first processed sample, and here is how distributions stack up:
| install | checkpoint | |
|---|---|---|
| Amazon Linux | 00:14 | 00:06 |
| SUSE Linux Enterprise Server | 00:04 | 03:13 |
| Red Hat Enterprise Linux | 00:05 | 03:15 |
| Ubuntu Server | 00:05 | 03:04 |
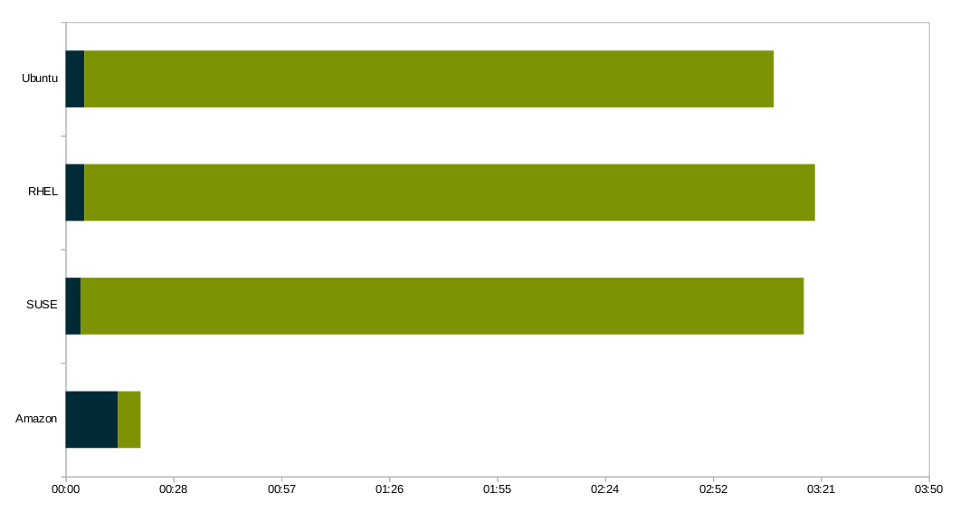
sherpa blue – bootstrap time; olive – processing first checkpoint
Given times are average of 3 VMs being bootstrapped and finalized processing 1000 cycles, when 1st checkpoint is created
While the bootstrap time varied between 4 and 14 minutes, initial checkpoint generation lasted between 6 minutes in case of Amazon Linux and ranged between 184 and 195 mins for the remaining three
All instances in test were, of course, identical. 12x t2.micro VMs with same amount of RAM, vCPUs and storage (1/1/EBS)
Checkpoint times are way off chart!
For some reason, Torch runs miraculously slow on all EC2 instance flavors (not including AWS Marketplace), except Amazon Linux, which is again based on RHEL, so something is a bit 🐟y here. Either optimizations Amazon made are astonishing, or they favor their distro over competition, resource-wise, under the hood
Any way you prefer, Amazon Linux, in spite of slower bootstrap, is the logical choice when it comes to char-rnn training, with cycles up to 10x faster than the rest
Playtime
Post bootstrap, all that remains is to aim a terminal to /opt/rnn-karpathy/,
provide a text source in data/input.txt (remove tinyshakespeare/) and fire
up sudo th train.lua -data_dir /opt/rnn-karpathy/data -gpuid -1
Console will display train loss, epoch and cycle duration and this is a great
time to thank the screen command and step away from the server, since
modeling will take some time
Processing duration differs based on the dataset size, but for a very rough
estimate – input.txt [1.06 MB], from char-rnn repo, on Amazon Linux instance
type t2.micro – takes about 24 hours to complete
Amid modeling, assuming you’re anxious to see preliminary results, start
another console and examine latest checkpoint file, as soon as cycles round up
to 1k. Head out to /opt/rnn-karpathy/ and sample with
sudo th sample.lua cv/* -gpuid -1
If, however, you want to test pre-provided input right away and generate some
of the Kind Richards paragraphs, Andrej neatly provided beforementioned
data/tinyshakespeare/input.txt
Here is the complete rundown on a fresh VM:
curl https://raw.githubusercontent.com/ushtipak/rnn-bootstrap/master/setup-rnn.sh | sudo bash
cd /opt/rnn-karpathy/
sudo th train.lua -gpuid -1
sudo th sample.lua cv/$(ls cv/ -1t | head -1) -gpuid -14 lines and about a day later, last command will provide output similar to:
RNN, much fun, very wow